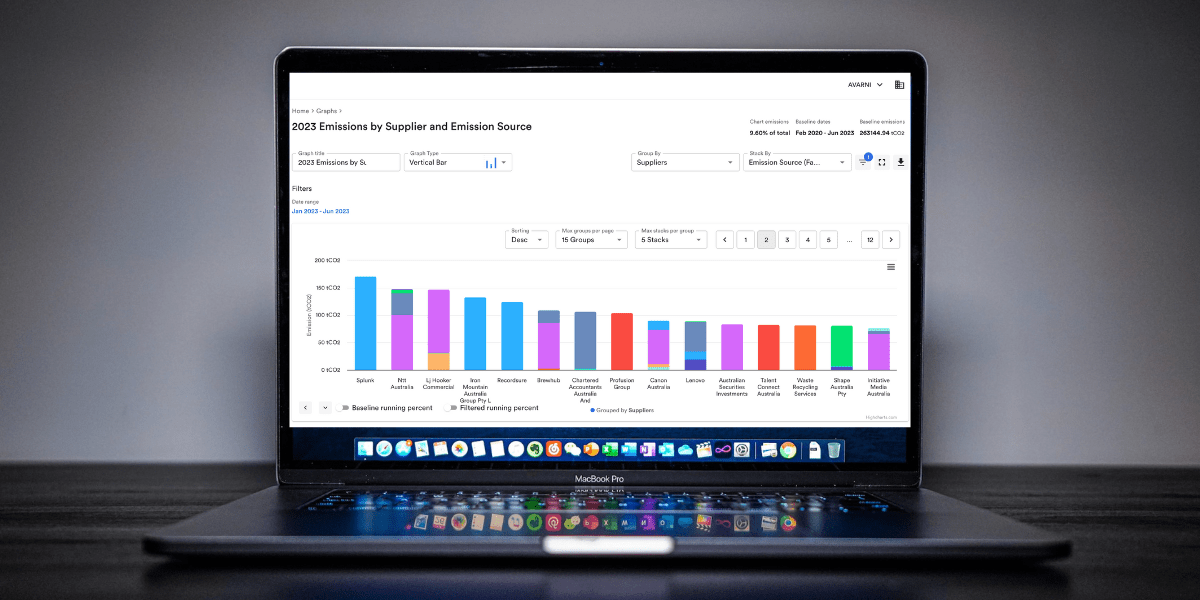
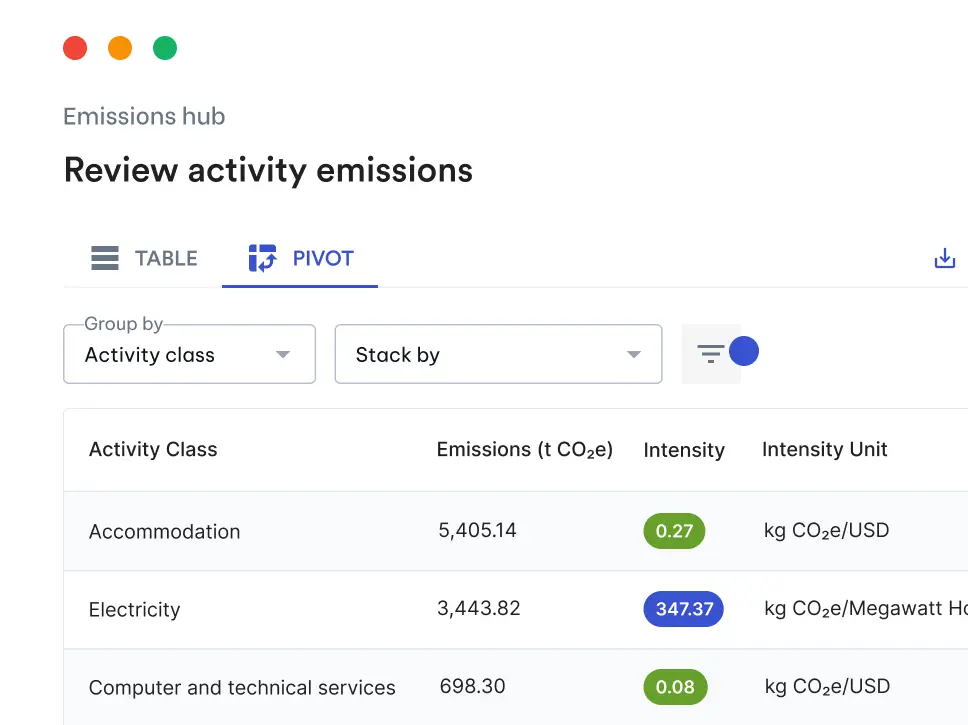
Welcome to the first post in a multi-part series exploring how we use AI at Avarni to to help companies track scope 3 emissions for ESG reporting. We get frequent enquiries about how we use AI to tackle climate change and over this series we’ll shed some light on some of the techniques and tools that our engineering team uses to power our AI systems.
Large language models (LLMs) form a critical part of our AI infrastructure. Working with them requires understanding of a broad range of techniques, and when and how to apply them, to consistently provide accurate and reliable calculations for our customers.
Retrieval-Augmented Generation (RAG) and fine-tuning are two such solutions, each addressing distinct limitations of LLMs. In the following we’ll outline the pros and cons of each approach and how we consider their application on our platform.
Shortcomings of today’s Large Language Models
Modern day LLMs, while powerful, have inherent limitations that can hinder their effectiveness in specialised applications:
- Limited context windows: LLMs can process only a fixed amount of text at a time (e.g., 16k tokens or 128k tokens), which constrains their understanding of longer documents or broader contexts.
- The “cut-off” date: LLMs are trained, sometimes for months, on a finite dataset. This means that this dataset has information only up to a certain date. You may have seen this sometimes referred to as the “cut-off” date for popular LLMs like ChatGPT. In practical terms this means that a LLM model will only have knowledge up until that particular date.
- Generic responses: Without domain-specific training, LLMs tend to generate more generalised responses that may not be accurate or relevant in specialised contexts.
Retrieval-Augmented Generation (RAG)
RAG tackles the issue of limited context windows and outdated information by dynamically retrieving external documents or data during the generation process. RAG is a technique that uses a two-step approach: first, it queries a large specialised database called a vector database for similar pieces of information, and then integrates this information into the model's context window and prompt.
Pros:
- Relevance and timeliness: By pulling from up-to-date external sources that you have in a vector database, RAG ensures that the information used in response generation reflects the latest data. Relevance in this context means relevance in meaning and not just similarities in characters or words.
- Expanded context: RAG effectively bypasses the context window limitation by bringing in external texts, allowing the model to consider a broader array of information than it could independently process.
Cons:
- Complexity and latency: The retrieval process adds computational overhead, potentially slowing down response times, which can be a drawback in certain applications
- Quality of sources: The effectiveness of RAG heavily depends on the quality and relevance of the retrieved data. Poor data sources can lead to inaccurate or misleading outputs. Building up a relevant knowledge base with high quality data drives the effectiveness of using RAG.
Fine-tuning
Fine-tuning involves retraining a pre-existing LLM on a specific dataset relevant to a particular domain, enhancing its ability to understand and generate domain-specific content accurately. This is different from using RAG in that instead of relying on querying for information in an external data store, we instead train new representations of domain specific knowledge into a new language model.
Pros:
- Domain expertise: Fine-tuning adapts the model to specific linguistic nuances and technical terms of a domain, making it more effective for specialised domain specific tasks (such as ESG reporting for example).
- Improved accuracy: By training on domain-specific data, the model can generate more accurate and contextually appropriate responses.
Cons:
- Data requirements: Effective fine-tuning requires large amounts of high-quality, domain-specific data, which can be challenging to gather and annotate.
- Overfitting risk: There is a risk that the model might become too specialised to the training data, reducing its ability to generalise from new or slightly different data types.
Practical application at Avarni
At Avarni, we consider the use of both RAG and fine-tuned models in our AI systems and actively evaluate which techniques will provide the most accurate and relevant answers for our customers. By using RAG, our AI can access the most current information, crucial for accurate scope 3 emissions tracking. Fine-tuning our own models on specialised ESG datasets can ensure that the AI not only accesses relevant information but also understands and applies it correctly within the specific framework and nuance of ESG reporting. The consideration of when or whether to apply these techniques was a key decision for how we designed our AI.
Conclusion
The choice between RAG and fine-tuning is a common decision when designing modern-day AI systems. In environments like Avarni's, where accuracy, timeliness, and domain-specific knowledge are critical, careful consideration of the pros and cons of each approach is necessary for a platform that is precise and consistently provides accurate answers for our customers.